
K-means
K-means 聚类算法是一种常用的基于距离的无监督学习算法,用于将数据集分成 K 个不同的簇。它试图通过最小化数据点与所属簇中心的距离来划分数据,使得每个数据点都属于与其最近的簇。
工作原理
K-means 算法的工作原理可以概括为以下几个步骤:
初始化:随机选择 K 个数据点作为初始簇中心。
分配数据点:对于每个数据点,计算它与每个簇中心的距离,并将数据点分配到与其最近的簇中心所对应的簇中。
更新簇中心:对于每个簇,重新计算该簇中所有数据点的均值,并将均值作为新的簇中心。
重复迭代:重复步骤2和步骤3,直到簇中心不再变化或达到预先设定的迭代次数。
收敛:当簇中心不再发生变化或者达到最大迭代次数时,算法停止迭代,得到最终的聚类结果。
优点
- 简单而且易于实现。
- 对大型数据集具有良好的伸缩性。
缺点
- 需要事先确定簇的数量 K。
- 对初始簇中心的选择敏感,可能会收敛到局部最优解。
- 对于不规则形状的簇效果不佳。
示例
Python
import numpy as np
import matplotlib.pyplot as plt
from sklearn.datasets import make_blobs
from sklearn.cluster import KMeans
# 生成示例数据
X, _ = make_blobs(n_samples=300, centers=4, cluster_std=0.6, random_state=0)
# 使用 K-means 聚类算法
kmeans = KMeans(n_clusters=4)
kmeans.fit(X)
y_kmeans = kmeans.predict(X)
# 绘制聚类结果
plt.scatter(X[:, 0], X[:, 1], c=y_kmeans, s=50, cmap='viridis')
centers = kmeans.cluster_centers_
plt.scatter(centers[:, 0], centers[:, 1], c='red', s=200, alpha=0.75)
plt.xlabel('X')
plt.ylabel('Y')
plt.title('K-means Clustering')
plt.show()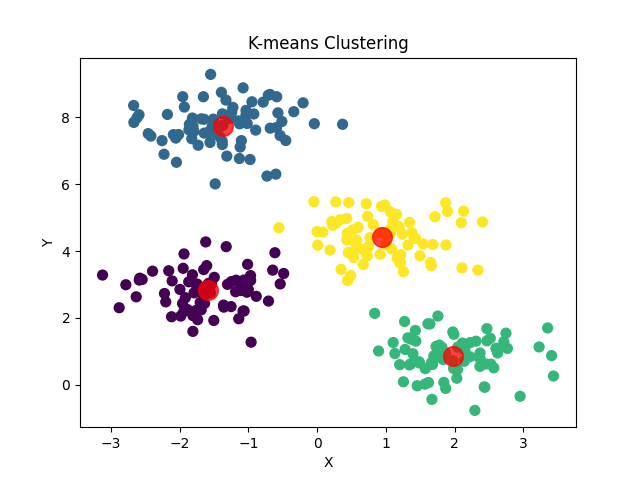
在这个示例中,我们首先使用 make_blobs 函数生成了一个随机的二维数据集,其中包含了四个簇。然后,我们使用 KMeans 类初始化了一个 K-means 聚类器,将簇的数量设置为 4,并将数据拟合到模型中。最后,我们绘制了聚类结果,其中不同的颜色代表不同的簇,红色点表示聚类中心。